
https://www.kaggle.com/datasets/vishalsubbiah/pokemon-images-and-types
Pokemon Image Dataset
Pokemon image dataset
www.kaggle.com
데이터 소개
이번 mini project는 캐글의 포켓몬 이미지 데이터셋을 활용하여 CNN을 활용한 이미지 분류를 진행하였다. 미니프로젝트 진행은 코렙에서 실행하였다. 포켓몬 이미지 데이터셋에서 주어진 데이터들은 포켓몬 이미지들과 각각의 포켓몬들의 타입들이 들어있는 csv 파일 하나가 들어있었다. 이 CNN을 활용해 이 포켓몬들의 이미지를 보고 type을 구분하는 것이 이번 프로젝트의 목적이다.


이미지 로드하기
코렙의 특성상 데이터를 바로 끌어다 쓰면 재실행 할때마다 계속 불러다 써야하는데 코렙에 마운트기능을 사용하여 드라이브에 저장시킨 데이터를 재실행 할 때마다 가져올 수 있게 만들어줬다. 그리고 os.listdir()를 사용하여 해당 디렉토리 내의 모든 파일 이름들을 리스트로 저장하였다.
일부 이미지 미리보기
포켓몬 이미지가 잘 불러와지는지 확인할 수 있는 함수를 만들었다. 여기서 image_label은 위에 os.listdir()로 불러온 것으로 for 문을 활용해야 함축되어있는 모든 파일들을 꺼낼 수 있다. 그렇게 꺼낸 이미지를 imread로 불러오고 imshow로 출력하게 일부 이미지를 가져왔다.

label 정리하기
csv 파일로 저장된 type들을 포켓몬 이미지의 이름에 맞는 type으로 라벨링을 해줘야한다. 일단 csv파일의 이름과 type을 zip 함수로 묶어준다.(여기서 type2는 사용하지 않는다.) 그리고 학습 가능한 형태로 만들어주기 위해 type을 숫자형태로 바꿔준다.


이미지 데이터셋 만들기
먼저 데이터 학습을 위해 이미지 크기를 일정하게 만들어주는 함수를 만들었다. 그리고 array 형태로 불러와 list형태로 넣어주는데 이때 사이즈 조정과 label 설정을 같이 설정해주는 함수를 만들었다. 이 함수를 사용하여 x와 y를 나누었다. x에는 이미지를 넣고 y에는 type을 넣어주었다. 그리고 다시 x, y 값을 np.array 형태로 만들어주었다.




train, valid로 나누기
y값을 기준으로 학습용 데이터셋과 검증용 데이터 셋을 만들어주기 위해 train_test_split을 사용하였다.

이미지 데이터 정규화
네트워크가 데이터를 처리하기 쉽게 만들어주기 위해 정규화 작업을 해주었다.

레이어층 만들기
이미지의 전처리를 위해 접고 돌리고 땡기는 작업을 해주었고 Conv2D와 MaxPooling2D를 사용하여 레이어층을 쌓았다. 마지막에는 3차원을 1차원으로 만들어주기 위해 Flatten을 사용하였고 출력층에 활성화 함수로 softmax를 사용했다.



Compile 만들기

학습하기
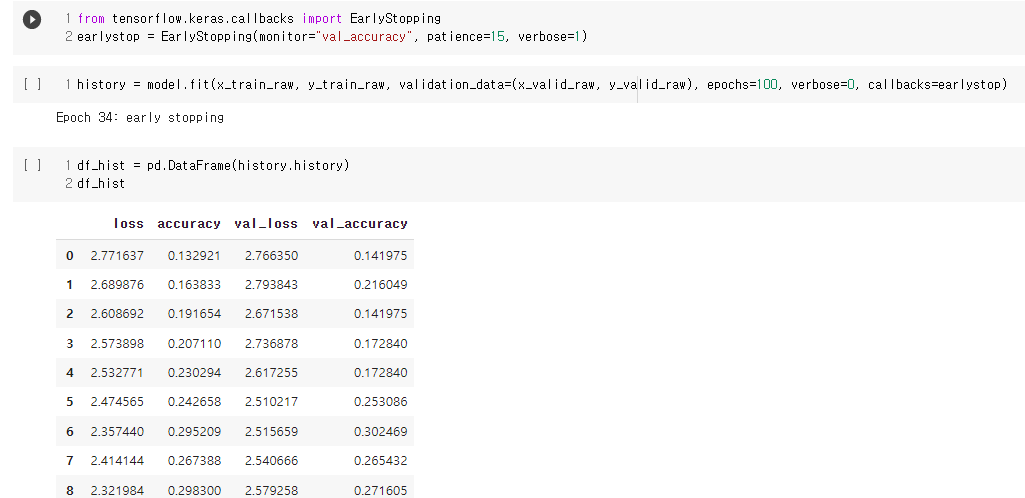
결과 시각화

느낀점
기존에 했던 머신러닝과는 많이 거리가 있는 느낌이다. 전체적인 흐름은 비슷하지만 피처엔지니어링을 따로 해주지 않아도 된다는 것이 조금 편했다. 하지만 성능을 올리는 방법이 너무 어렵다. baseline을 만들어 layer층을 많이 쌓기 전이 가장 성능이 좋았다. 접고 돌리고 땡기는 전처리를 하고 layer층을 한층씩 더 쌓을 때마다 성능이 떨어진다. 어떤식으로 해야 성능이 오르는 지는 아직 잘 모르겠다. 하지만 CNN을 활용하여 이미지 분류를 해봤다는 것에 내가 성장했음을 느꼈다.
'멋사 AI SCHOOL에서' 카테고리의 다른 글
| [AI SCHOOL] Final_Project (주제: 도서 추천 시스템 만들기) (1) | 2023.01.16 |
|---|---|
| [AI SCHOOL] Mini_Project_3 (주제: 신용카드 사용자 연체 예측) (1) | 2022.11.05 |
| [AI SCHOOL] Mid Project (19일 ~23일) (0) | 2022.10.24 |
| [AI SCHOOL] Mini_Project_2 (주제: 서울시 편의점 데이터 분석) (0) | 2022.10.18 |
| [AI SCHOOL] Mini_Project_1 (주제:국내 프랜차이즈 카페 전국 매장 정보) (0) | 2022.10.08 |


